
AI NEEDS CULTURAL POLICIES, NOT JUST REGULATION
Relevance:
- GS 2 – Government policies and interventions for development in various sectors and issues arising out of their design and implementation
- GS 3 – Awareness in the fields of IT
Why in the news?
- Fair and wide access to data is essential for realizing AI’s full potential and distributing its benefits equitably.
- “Data are the lifeblood of AI.”
- The future of Artificial Intelligence (AI) cannot be secured by regulation alone.
- To ensure safe and trustworthy AI for all, we must balance regulation with policies that promote high-quality data as a public good.
More about the news:
- This approach is crucial for:
- Fostering transparency
- Creating a level playing field
- Building public trust
- The laws of neural scaling are simple: the more data, the better.
- Greater volume and diversity of human-generated text improve the performance of Large Language Models (LLMs) in unsupervised learning.
- Alongside computing power and algorithmic innovations, data are arguably the most important driver of progress in the AI field.
Fears of an ‘AI Winter’:
- Societal interest and disinterest in artificial intelligence (AI) follow a natural pattern.
- AI Winters is the period when interest and funding in AI decrease significantly but they do not stop altogether.
- Problem with Data Supply:
- Humans do not produce enough digital content to meet the growing demands of AI.
- Current training datasets are already massive;
- For instance, Meta’s LLama 3 is trained on 15 trillion tokens, over 10 times the British Library’s book collection.
- A recent study suggests we might reach ‘peak data’ before 2030 due to the high demand for pristine text.
- Other studies warn of the dangers of public data contamination by LLMs, causing feedback loops that amplify biases and reduce diversity.
- Data at expense of Ethics: The relentless race for data can come at the expense of quality and ethics.
- An example is ‘Books3’, a collection of pirated books used to train leading LLMs, raising legal and ethical concerns. These books are hoarded without clear guiding principles, sparking debates about fair-use policy.
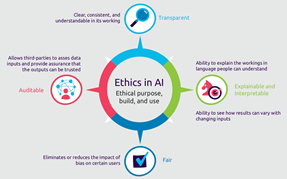
Current State of LLM Training:
- The idea that LLMs are trained on a universal compendium of human knowledge is a misconception.
- Current LLMs are not the universal library envisioned by Leibniz and Borges.
- Despite progress and regulation, LLMs are still largely trained on a mix of licensed content, publicly available data, and social media interactions.
- Studies indicate that these data sources reflect and sometimes exacerbate distortions in cyberspace, creating an overwhelmingly anglophone and presentist world.
- Collections like ‘Books3’ may include some scholarly works, but these are largely secondary sources written in English, providing only superficial coverage of human culture.
Untapped Reservoir of Linguistic Data:
- Primary sources represent a vast, untapped reservoir of linguistic data.
- Primary sources, such as archival documents, oral traditions, and ancient inscriptions, are largely absent.
- Example: Italy’s State Archives alone hold 1,500 kilometres of shelved documents, not including the Vatican’s holdings.
- The total volume of tokens from global archives could match or exceed the data currently used to train LLMs.
Potential Benefits of Using Primary data:
- Cultural Wealth of Humanity: Harnessing these primary sources would enrich AI’s understanding of humanity’s cultural wealth and make it more accessible.
- It could revolutionize our understanding of history and safeguard cultural heritage from negligence, war, and climate change.
- Economic benefits:
- Helping neural networks scale up.
- Providing large pools of free, transparent data for smaller companies, startups, and the open-source AI community.
- Leveling the playing field against Big Tech and fostering global innovation.
| Learnings from Italy and Canada
Italy’s Initiative:
Canada’s Official Languages Act:
|
Overlooked Potential of Regional Languages
- Current Debates:
- Recent discussions in the Spanish Cortes and European Union institutions about adopting regional languages have missed a crucial point.
- Advocates have not fully recognized the cultural, economic, and technological benefits of promoting the digitization of low-resource languages.
- Importance of Digitizing Cultural Heritage:
- As we accelerate the digital transition, we must not overlook the immense potential of our world’s cultural heritage.
- Advances in Digital Humanities: AI has drastically reduced the cost of digitization.
- Enabled extraction of text from printed and manuscript documents with unprecedented accuracy and speed.
- Digitization is key to:
- Preserving history
- Democratising knowledge
- Unleashing truly inclusive AI innovation
Way forward
To effectively harness the potential of digitizing cultural heritage for AI development, the following steps can be taken:
- Prioritize Digitization Projects:
- Governments and cultural institutions should allocate resources to digitize primary sources and regional language materials.
- Establish partnerships with tech companies and research organizations to support these initiatives.
- Ensure Open Access:
- Adopt open data policies to make digitized cultural heritage freely available for public use and AI training.
- Develop robust data governance frameworks to protect intellectual property rights and privacy concerns.
- Promote Multilingual AI:
- Encourage the development of AI models that can understand and generate content in multiple languages, including low-resource and regional languages.
- Support research and development in natural language processing for underrepresented languages.
- Enhance Digital Humanities:
- Invest in interdisciplinary research that combines expertise from humanities, social sciences, and computer science.
- Develop educational programs and training opportunities to bridge the gap between cultural heritage and AI.
- Foster International Collaboration:
- Establish global partnerships and knowledge-sharing platforms to exchange best practices and lessons learned in digitizing cultural heritage.
- Collaborate on creating standardized guidelines and protocols for digitization and data management.
- Raise Public Awareness:
- Engage in public outreach campaigns to highlight the importance of preserving cultural heritage in the digital age.
- Encourage citizen science initiatives that involve the public in digitization efforts and data annotation tasks.
- Develop Ethical AI Frameworks:
- Ensure that AI development based on cultural heritage data adheres to ethical principles, such as fairness, transparency, and accountability.
- Establish guidelines for the responsible use of cultural data in AI systems to prevent misuse or misrepresentation.
Alternative articles
- https://universalinstitutions.com/regulating-artificial-intelligence-building-regulatory-capabilities/
- https://universalinstitutions.com/the-need-for-an-indian-system-to-regulate-ai/
- https://universalinstitutions.com/an-ai-infused-world-needs-matching-cybersecurity/
Mains question
Discuss the importance of digitizing cultural heritage in the context of AI development. How can this process contribute to preserving history, democratizing knowledge, and fostering inclusive innovation? (250 words)


